Loading blog posts...
Back to Blog
Also in
Claude Code feels amazing for 10 minutes, then suddenly it starts missing constraints, rewriting the wrong files, or "forgetting" decisions you made earlier. From what I've seen, that drop-off usually isn't the model being "bad." It's almost always context-window management plus a lack of durable, repo-specific rules.
Below are the Claude Code best practices teams are using in 2026, with copyable patterns and a production-ready CLAUDE.md that helps keep results consistent across sessions and developers.
Context-window management: stop paying for your own noise
Here's the deal: one of the most common mistakes is pasting a 2,000-line build log and asking "what happened?" Claude will take a swing, sure, but you've basically spent most of your context window on text that won't matter five minutes later.
bash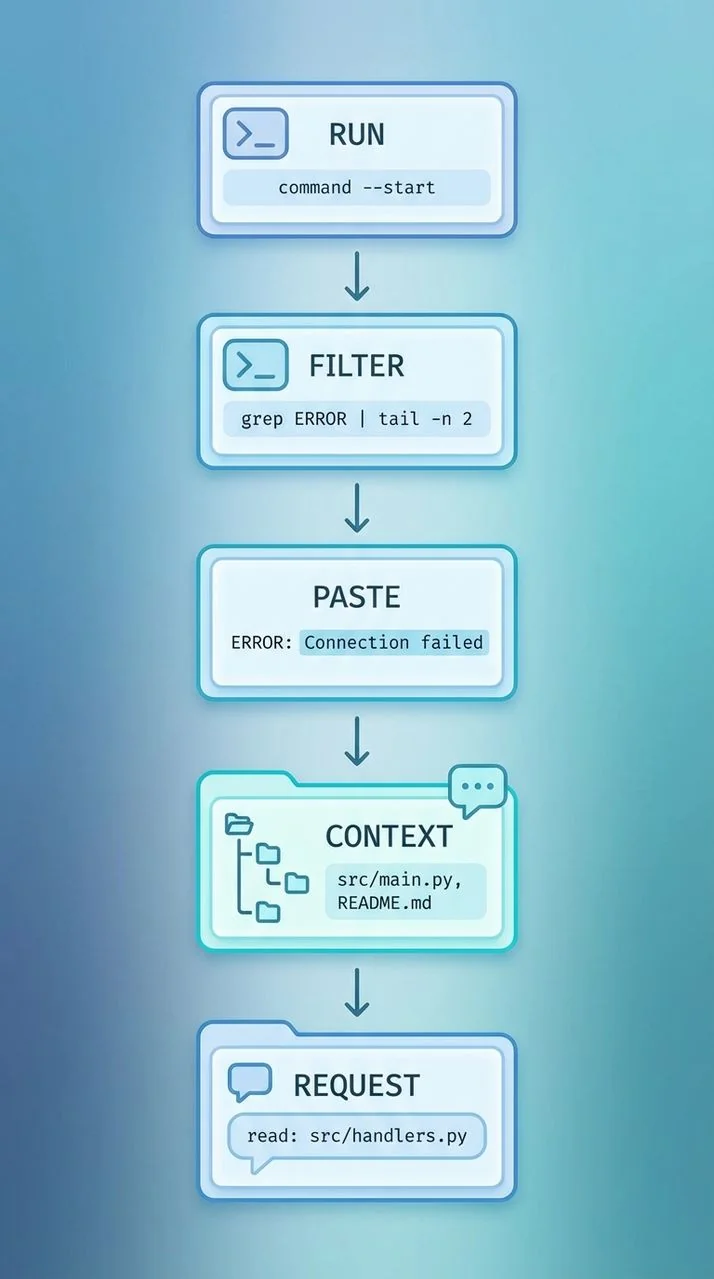 ## Good workflow: summarize logs locally, then paste only the summary + a few critical lines pytest -q 2>&1 | tail -n 80 # Or capture full logs to a file and paste only the relevant excerpt pytest -q 2>&1 | tee /tmp/test.log rg -n "FAIL|ERROR|Traceback" /tmp/test.log | head -n 40
The model's context window is finite, and it tends to get less reliable as it fills up with chat history, pasted files, and verbose output. The practical consequence is pretty simple: treat context like RAM. Keep only what the agent needs to decide the next change, not everything you saw while debugging (tempting as that is).
Tip
When output is long, paste: 1) the command you ran, 2) the top error line, 3) 20 to 80 lines around the failure, 4) what you already tried.
If the task needs multiple files, don't dump them all up front. Give a map first, then pull in only the files Claude asks for.
textRepo map: - apps/web: Next.js app, routes in app/ - packages/ui: shared components - packages/api: tRPC router + zod schemas Goal: fix login redirect loop in apps/web. Files likely involved: apps/web/middleware.ts, apps/web/app/login/page.tsx Do not touch: packages/ui
This "repo map then request" pattern keeps the model thinking about architecture and intent, not drowning in raw text. It also cuts down on accidental edits in unrelated areas because the boundary is explicit. For official guidance on this constraint, see Best Practices for Claude Code.
Boundary-first prompting: scope, non-goals, acceptance criteria
Most Claude Code failures I see in real repos look like this: the agent tries to be helpful and quietly expands scope. The fix is to make boundaries executable, not aspirational.
textTask: Add request-id propagation to our Node API. Scope: - Add `x-request-id` generation if missing. - Propagate to downstream fetch calls. Non-goals: - No logging changes. - No refactor of fetch wrapper. Acceptance criteria: - Unit test proves header is set and forwarded. - No public API shape changes. Required commands: - pnpm test --filter api
This works because it turns "do the right thing" into a checklist Claude can actually satisfy. Under the hood, you're reducing ambiguity, which means the agent is less likely to invent extra changes just to feel "done."
Warning
If you omit "Do not touch" and "Non-goals", Claude often "cleans up" code style or types across files, which creates noisy diffs and slows review.
A habit I strongly recommend: require a plan before edits when the change crosses module boundaries.
textBefore coding: 1) List files you will change. 2) For each file, describe the minimal edit. 3) Confirm tests you will run. Wait for approval, then implement.
That one step catches a lot of "wrong layer" mistakes early because you can veto file choices before any code changes land.
CLAUDE.md: the repo operating manual that prevents repeat prompting
Start with a CLAUDE.md that is short, scannable, and enforceable. Don't write a manifesto. Write the rules that prevent expensive mistakes - the ones you keep repeating in code review.
md## CLAUDE.md ## How to work in this repo - Default branch: `main` - Package manager: `pnpm` (do not use npm/yarn) - Node version: 20.x (see `.nvmrc`) - Formatting: run `pnpm lint` before final output ## Repo layout - `apps/web`: Next.js 15 app router - `apps/api`: Node API (Fastify) - `packages/shared`: shared types and utilities ## Do - Keep changes minimal and scoped to the task. - Add or update tests for behavior changes. - Prefer existing utilities over adding new dependencies. ## Don't - Do not rename public exports without approval. - Do not reformat unrelated files. - Do not change database migrations unless explicitly requested. ## Commands - Install: `pnpm i` - Tests: `pnpm test` - Web tests: `pnpm test --filter web` - API tests: `pnpm test --filter api` - Lint: `pnpm lint` - Typecheck: `pnpm typecheck` ## Code style rules - TypeScript: no `any` unless justified in a comment. - React: prefer server components unless client state is required. - Error handling: return typed errors, no stringly-typed error codes. ## PR checklist - Diff is minimal and matches scope. - Tests added/updated and passing. - No secrets in code or logs.
This matters because it turns "tribal knowledge" into durable instructions that persist across chats and across developers. Claude follows instructions hierarchically, so a repo-level CLAUDE.md can override generic defaults while still fitting org-wide standards (which is exactly what you want).
Teams that keep CLAUDE.md short usually get better adherence. Long docs get ignored because they're hard to scan and expensive to load into context. For deeper examples and structure ideas, see The Complete Guide to CLAUDE.md, Creating the Perfect CLAUDE.md for Claude Code, and the curated patterns in Awesome Claude.md.
CLAUDE.md templates that scale across teams
The fastest way to standardize is a two-layer setup: org defaults plus repo overrides. Keep org defaults tiny and universal, then let each repo specify commands, layouts, and sharp "don't" rules.
md# [ORG] Claude defaults (share internally) ## Non-negotiables - Keep diffs small and reviewable. - Never change unrelated formatting. - Always state commands needed to validate changes. ## Output rules - Provide file paths for edits. - Include test commands to run. - If uncertain, ask one clarifying question, then proceed.
Then in each repo, CLAUDE.md focuses on what's unique: architecture constraints, build commands, and forbidden refactors. This prevents a common failure mode where generic "best practices" collide with repo reality.
One pattern I like (because it's practical) is encoding "safe refactor corridors" instead of banning refactors outright.
md## Safe refactors (allowed without extra approval) - Rename local variables inside a single function. - Extract helper functions within the same module. - Replace duplicated literals with existing constants. ## Refactors that require approval - Moving files across packages - Changing public exports - Introducing new runtime dependencies
This makes Claude faster because it doesn't have to guess what level of change is acceptable. Review speeds up too because the diff shape matches what the team expects. For team rollouts and "skills" style presets, see Claude Skills and CLAUDE.md: a practical 2026 guide for teams.
Tooling stack: the 2026 setup that keeps Claude honest
Claude Code works best when it can verify changes with real commands. The "tools list" below is less about what's trendy and more about keeping feedback loops tight (because tight loops are what keep agents honest).
Claude Code (agentic coding in your repo)
Claude Code runs tasks inside your project and can edit files, run tests, and iterate. It matters because the model can close the loop by validating assumptions with commands instead of guessing.
textClaude Code task format to paste into chat: - Goal: [ONE sentence] - Scope: [2-5 bullets] - Non-goals: [2-5 bullets] - Files: [explicit list or "ask first"] - Commands: [exact commands] - Acceptance criteria: [testable outcomes]
When teams adopt this format, they reduce "agent drift" where the model changes extra layers to feel thorough. It also makes PR review faster because the diff aligns with the declared scope.
Docs: Claude Code Best Practices
GitHub Actions (CI that mirrors the commands in CLAUDE.md)
GitHub Actions runs the same test and lint commands Claude is told to run locally. It matters because it prevents "works on my machine" and forces the agent to respect the repo's real gates.
yaml#.github/workflows/ci.yml name: ci on: [pull_request] jobs: test: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - uses: pnpm/action-setup@v4 with: version: 9 - uses: actions/setup-node@v4 with: node-version-file: .nvmrc cache: pnpm - run: pnpm i --frozen-lockfile - run: pnpm lint - run: pnpm typecheck - run: pnpm test
Don't skip the boring part: mirror CLAUDE.md commands exactly. If CLAUDE.md says pnpm typecheck but CI runs something else, Claude will "pass locally" and fail in CI, and you'll burn time for no good reason.
pre-commit + lint-staged (catch bad diffs before Claude finishes)
Pre-commit hooks stop accidental formatting blasts and missing lint fixes. It matters because Claude can generate correct logic but still miss a formatting or import rule your repo enforces (it happens).
json// package.json { "lint-staged": { "*.{ts,tsx,js,jsx}": [ "eslint --fix", "prettier -w" ], "*.{md,json,yml,yaml}": [ "prettier -w" ] } }
This reduces review noise and protects the "minimal diff" rule. It also makes Claude's output more predictable because the final diff shape is enforced mechanically.
Ripgrep (fast code search that keeps context small)
Ripgrep (rg) finds references without loading entire files into the chat. It matters because you can answer "where is this used?" with 10 lines of output instead of 500.
bash## Find where a header is set or forwarded rg -n "x-request-id|request[-_]?id" apps packages # Find the exact handler for a route rg -n "GET\\s+/login|/login" apps/web
The consequence is fewer "context dumps." Claude gets targeted snippets, so it's less likely to make broad edits.
Alternatives: when Claude Code is not the right fit
Sometimes the best practice is picking a different tool for the task.
| Tool | Where it shines | Trade-offs | Best for |
|---|---|---|---|
| Claude Code | Multi-step repo changes with tests | Needs strict scope to avoid drift | Refactors, feature slices |
| GitHub Copilot | Inline completion and quick edits | Less "project memory" unless guided | Small edits, boilerplate |
| Cursor | IDE-first agent workflows | Easy to over-edit without rules | UI work, rapid iteration |
| ChatGPT (web/app) | Broad reasoning and explanations | Harder to run repo commands | Architecture discussion |
If the job is "explain this error" or "design an interface," a chat-only tool is often enough. If the job is "change code and prove it passes," Claude Code plus enforced commands is usually the safer path.

Creative prompts that prevent common Claude Code failures
When Claude starts oscillating or changing too much, I switch to "diff discipline" prompts. They're simple, but they change behavior fast.
Use this when the model keeps refactoring unrelated code.
textOnly make changes required to satisfy the acceptance criteria. If you touch a file, justify why it must change. Prefer adding code over moving code. Return a file-by-file patch plan before editing.
Use this when the model keeps asking for more context.
textAssume missing details are unknown. Ask at most 2 clarifying questions. If still blocked, propose 2 options with trade-offs and pick one to implement.
Use this when tests are slow and Claude tries to skip them.
textYou must run the fastest relevant test subset first. If it passes, run the full suite. Report the exact commands and summarized results.
These prompts work because they explicitly optimize for bounded changes and verification. Without that, an agent tends to optimize for "completeness," which often turns into scope creep.
For more community patterns, see the discussion thread: What are your best practices for Claude Code in early 2026?
Measurable outcomes: what "good" looks like in production teams
The goal isn't "more AI." It's fewer review cycles and fewer regressions from agentic edits.
| Metric to track | Target | How to measure | What it tells you |
|---|---|---|---|
| PR review rounds | 1-2 rounds | GitHub PR timeline | Scope clarity and diff quality |
| CI failure rate on AI PRs | < 10% | Workflow runs tagged by author | Whether CLAUDE.md commands match CI |
| Average diff size | < 300 lines | GitHub diff stats | Whether "minimal diff" rules stick |
| Time-to-merge | 1 day median | PR opened to merged | End-to-end throughput |
Some well-known engineering orgs have shown the value of tight loops and automation. Netflix reported cutting deployment time from hours to minutes with Spinnaker-style automation, a shift that made small, verifiable changes the norm. Stripe has discussed keeping developer velocity high through strong internal tooling and fast CI feedback loops. Shopify has shared that reducing CI time and improving build reliability directly improves developer throughput and lowers change risk.
Those examples aren't "Claude metrics," but they map to the same principle: the faster the feedback loop, the smaller and safer the change set.
If your team is also modernizing the web stack, the same "small diffs, fast verification" philosophy applies to frameworks too. See Next.js 15: The Complete Guide to React's Most Powerful Framework for patterns that keep changes reviewable in App Router codebases.
Quick Wins
Start here (your first step)
Add a CLAUDE.md with only: commands, repo layout, 5 "Do" rules, 5 "Don't" rules.
Quick wins (immediate impact)
- Replace "paste the whole log" with: command + 40 lines around the error + what changed since last green build.
- Require every Claude task to include
Scope,Non-goals, andAcceptance criteriain the first message.
Deep dive (for those who want more)
- Add a "Safe refactors vs approval required" section to
CLAUDE.md, then enforce it in PR review for 2 weeks. - Track AI-authored PR CI failure rate for 20 PRs and update
CLAUDE.mdto match the real CI commands.
Useful Resources
- Best Practices for Claude Code - Official guidance focused on context-window constraints and reliable workflows.
- Creating the Perfect CLAUDE.md for Claude Code - Practical structure patterns and enforceable sections.
- The Complete Guide to CLAUDE.md - Examples and maintenance advice for evolving repos.
- Claude Skills and CLAUDE.md: a practical 2026 guide for teams - Team standardization and rollout checklists.
- Awesome Claude.md - Curated real-world
CLAUDE.mdexamples and templates.
The Bottom Line
Claude Code in 2026 is less about clever prompts and more about operational discipline: keep context small, set hard boundaries, and make validation commands non-optional. In my experience, a maintained CLAUDE.md is the highest-ROI change because it turns "how we work here" into durable, scannable rules that survive across sessions. Teams that treat the context window like a scarce resource get more correct diffs, fewer CI surprises, and faster merges.


